Harnessing Scikit-LLM for Text Summarization
Within this article, we're set to explore how to efficiently utilize the text summarization capabilities of scikit-LLM, a tool designed for streamlining text processing in machine learning workflows.
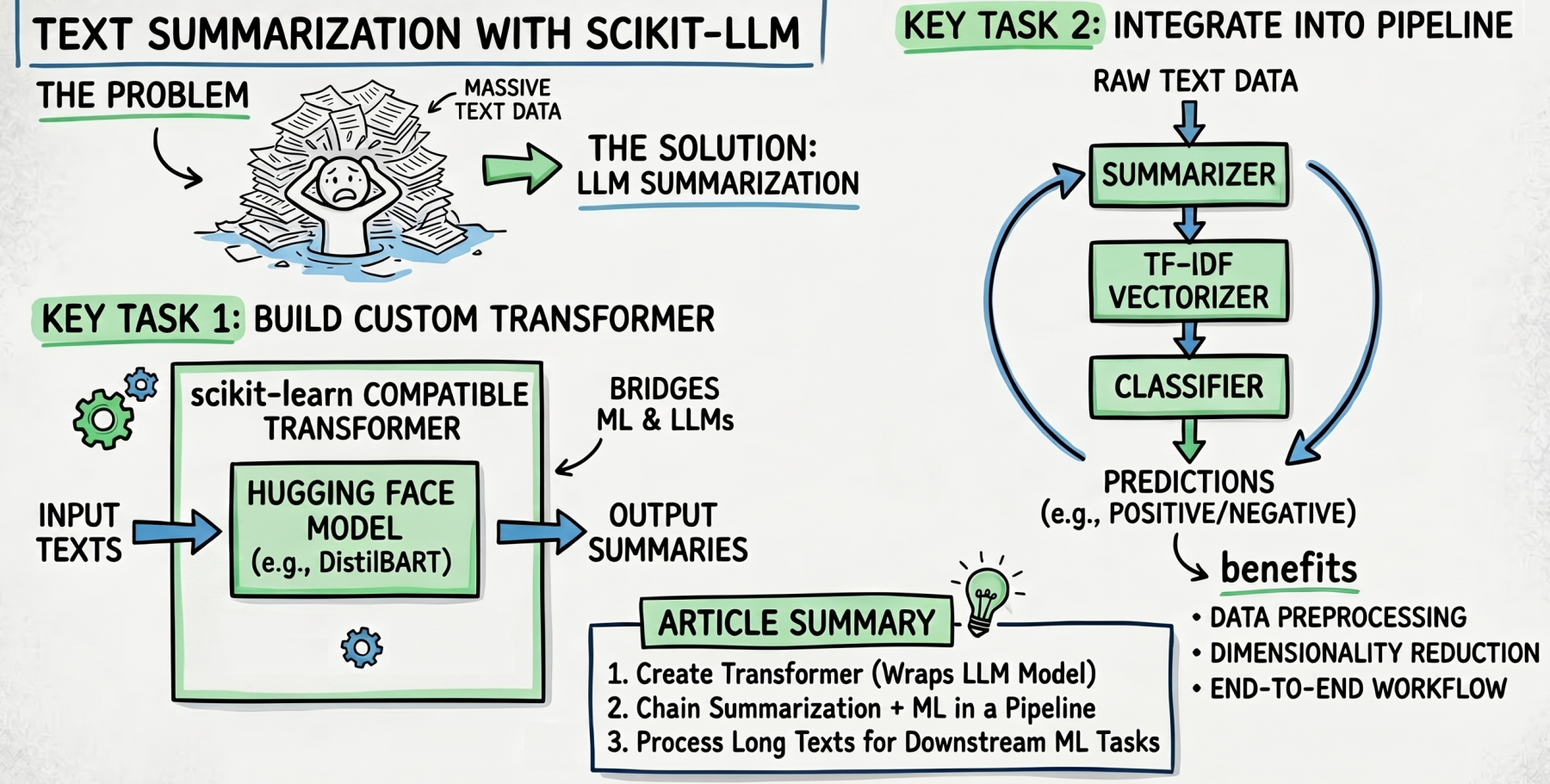
We will examine:
- The method for creating a custom transformer that integrates with Hugging Face’s summarization models.
- How to weave LLM-based summarization into a broader scikit-learn pipeline for preprocessing data.
- Strategies for combining summarization, TF-IDF vectorization, and classification into a cohesive end-to-end workflow.
Text Summarization with Scikit-LLM
Image by Editor
Introduction
In our previous discussion, we showcased scikit-LLM and its ability to connect classical machine learning approaches with advanced large language models (LLMs). Specifically, we focused on implementing zero-shot and few-shot classification tasks.
Now, we seek to address a pressing issue: What happens when excessive amounts of text overload our downstream processes? To tackle this and enhance efficiency, we will focus on summarization—a feature within the library designed to condense lengthy documents into concise summaries. Let’s dive into the mechanics of building a data preparation pipeline that incorporates this pivotal step!
Initial Setup
Begin by ensuring you have scikit-LLM installed. If you're operating within a cloud-based notebook, substitute "pip" with "!pip":
Keep in mind that scikit-LLM defaults to OpenAI's language models, which can incur high costs and may have restricted usage under free accounts. Instead, consider deploying accessible pre-trained models from Hugging Face for summarization, like sshleifer/distilbart-cnn-12-6. You'll also need to install the Hugging Face Transformers library to access these models in your applications.
Implementing a Summarization Pipeline
The following class encapsulates the logic necessary to load a pretrained model for summarization and process input texts to produce concise summaries:
Building a Custom Summarizer
We've set the stage with a custom class that leverages the Hugging Face library to perform summarization. This design not only showcases the power of LLMs but also emphasizes how they can be integrated into traditional machine learning workflows. Our `HuggingFaceSummarizer` class is derived from `BaseEstimator` and `TransformerMixin`, classes that are pivotal for compatibility with
scikit-learn tools. This integration allows users to apply scikit-learn's familiar structure and methods directly to LLMs, which is quite significant for practitioners looking to enhance their text processing capabilities. Notably, this fusion simplifies the transition into using advanced models without requiring a deep dive into their underlying architectures.
For demonstration, we will summarize two text reviews, which are integral to a more extensive dataset intended for a sentiment analysis classifier. Here's how our sample data might appear:
```python
X_long_texts = [
"I've been using this vacuum cleaner for about three weeks now. At first, I struggled with the attachments, and the manual wasn't very clear. However, once I figured out how the motorized brush works, it easily picked up all the pet hair on my rugs. Overall, it's a solid machine, though a bit heavy to carry up the stairs.",
"The delivery was delayed by four days, which was incredibly frustrating because I needed it for a weekend trip. When the backpack finally arrived, the zipper snagged immediately. I tried to fix it, but the fabric feels cheap and flimsy. I will definitely be returning this and asking for a full refund.",
]
y_labels = ["positive", "negative"]
```
Here, the long text inputs represent different consumer reviews, while the associated sentiment labels denote their overall tone.
From Summarization to Action
This is where the process begins to demonstrate its value. By summarizing lengthy text inputs, we're not just condensing information—we’re effectively cutting down the noise and enhancing the focus on key sentiments. It’s something critical in fields like sentiment analysis where every bit of context can sway interpretations.
After defining the class and preparing our sample data, we create a pipeline that integrates the summarization process with the classification training. Sure, for any practical classifier, you would need a significantly larger dataset than the two examples provided here. However, this simple pair effectively illustrates how text summarization can streamline the data by reducing dimensionality.
With the model in place, you’ll find that the summarization not only enriches the feature set but also helps improve the classifier's predictive accuracy. By narrowing down the data inputs, you make the resultant model simpler and easier to train. Which raises the question: how can you leverage such summarization utilities in your own projects to yield more effective models? The potential is certainly there, especially when dealing with voluminous text data.
Concluding Insights: The Future of Text Classification Pipelines
As we wrap up this exploration into the mechanics of text classification with machine learning, it's clear that building efficient pipelines is not merely a technical exercise—but a foundational skill for modern data scientists. The example pipeline we examined, which integrates summarization, vectorization, and classification, illustrates a growing trend toward more nuanced processing of textual data.
What stands out here is the seamless integration of various components. The choice to utilize a summarization model like HuggingFaceSummarizer can significantly streamline the input, ensuring that the classifier operates on digestible summaries rather than exhaustive texts. If you're immersed in this field, you likely recognize the challenge of balancing accuracy and efficiency. This pipeline does just that, representing a thoughtful approach to pre-processing steps that could improve the overall model performance.
But here’s something to ponder: while this example showcases a solid implementation using Logistic Regression, the underlying philosophy could be at risk of becoming overly simplistic as demands for more complex interpretations of text data grow. Machine learning, particularly in natural language processing, continues to evolve rapidly. Are linear models enough to capture the subtleties of language in every context? It’s uncertain. As language models advance, we may need to rethink our traditional classifiers.
Training this pipeline only requires a simple call to the `fit()` method on your lengthy dataset and labels, but the journey doesn’t end there. You’ll want to explore how well this pipeline generalizes across different datasets. The nuance of language and context can vary tremendously—what works for one set of reviews may falter under a different domain.
As we look to the future, refining these pipelines with techniques such as hyperparameter tuning or even experimenting with advanced models could yield more robust insights. The landscape of text classification is vast and filled with potential; what you choose to build today might pave the way for tomorrow's breakthroughs. Overall, understanding and optimizing these pipelines isn't just useful; it's a necessary endeavor in staying ahead in the evolving tech ecosystem.

