This in-depth guide will explore the concept of context management and its importance in ensuring AI agents remain reliable, efficient, and precise when deployed in real-world scenarios.
We'll discuss several key aspects, including:
- The necessity of viewing the context window as a limited resource and the implications of poor token management.
- The art of organizing context layers — distinguishing static information from dynamic interactions, managing historical data, and strategically designing retrieval processes.
- Techniques for assessing context quality in active deployments through targeted evaluations and specific metrics.
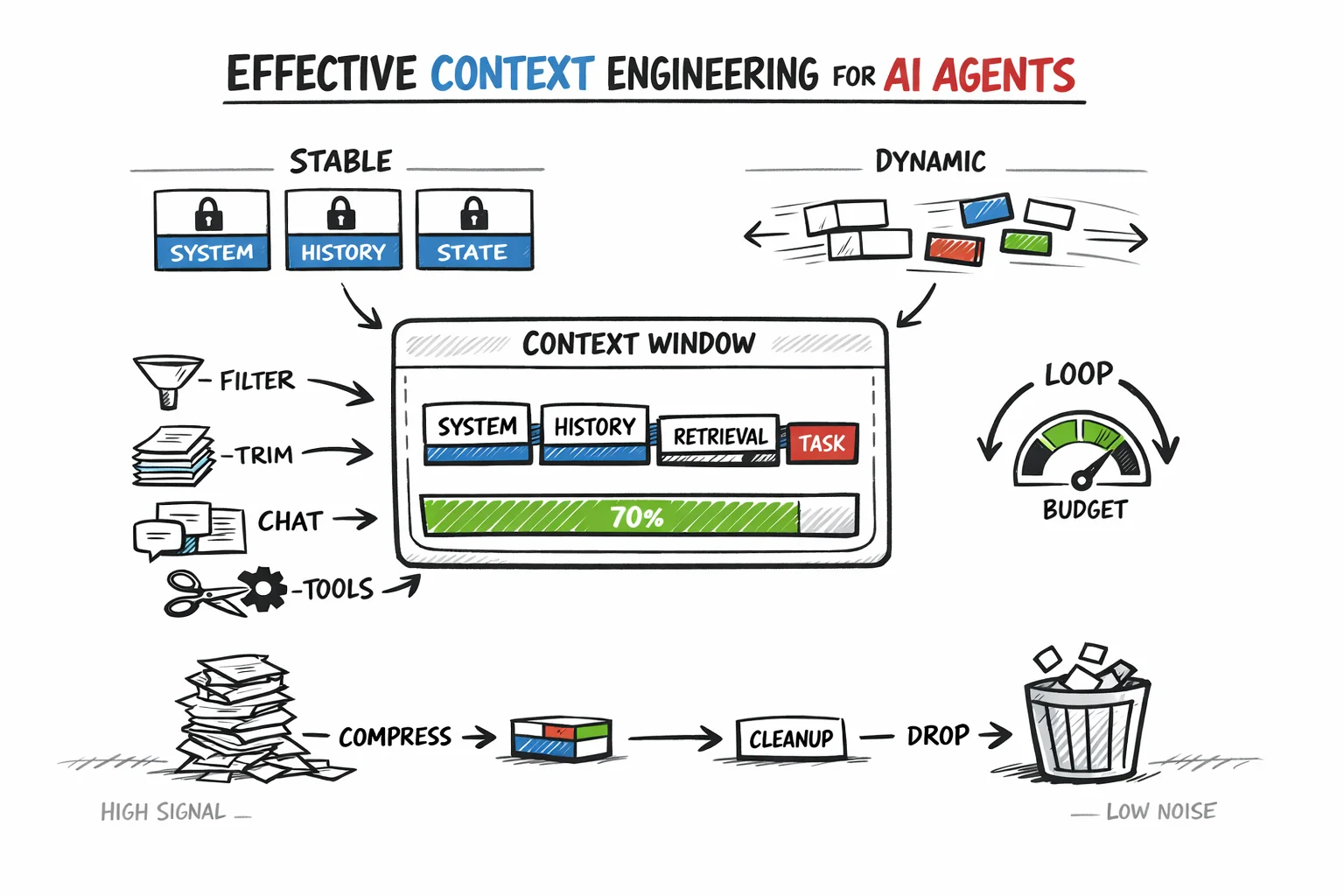
Mastering Context Management for AI Agents: A Developer’s Guide
Image by Author
Introduction
When AI agents fail in practical applications, the root cause often lies not in the algorithms but in the mismanagement of the context window. This window tends to become overloaded with irrelevant historical data, unnecessary retrieval outputs, and excessive information that obscures the critical insights the model needs.
Context management, or context engineering, involves strategic choices about what information enters the context window, what gets condensed, what is fetched as needed, and what can be omitted altogether. Effective management helps retain high-quality tokens essential for minimizing both costs and performance issues that arise from careless context accumulation.
This article outlines several foundational principles:
- Recognizing the context window as a finite resource
- Creating a clear distinction between static and dynamic context
- Overseeing history, retrieval, and token budgets within the agent cycle
- Assessing and maintaining context quality in production environments
Each of these principles builds upon the others, establishing a systematic approach that ensures agents function reliably under the demands of real-world usage.
Treating the Context Window as Finite Resource
The context window is pivotal in shaping decisions throughout agent architecture. Unfortunately, many implementations mishandle it by treating it merely as a technical hurdle to bypass rather than a fundamental design element.
There are two significant costs to consider regarding tokens: financial and cognitive. Financially, the expenses are straightforward since models incur charges for every million input tokens, and these can accumulate swiftly in multi-step workflows.
Cognitive costs, though less visible, are equally critical. Models prioritize information, often focusing on the beginning and end of the context, while the content found in the middle can lose significance. Thus, lengthy or poorly organized inputs can hinder reasoning, even if they fit within the token restrictions.
A useful analogy is to view the context window as akin to RAM; it’s fast and efficient but also limited and erased after each session. Conversely, external systems, much like databases or file storage, provide higher capacity at a lower cost but require specific retrieval requests to be effective.
Effective context management hinges on determining what should reside in RAM at any given instant and what can wait in long-term storage. Google’s Agent Development Kit (ADK) emphasizes that the common practice of simply appending all data into one massive prompt ultimately falls short due to three main pressures: rising costs and latency, a decrease in signal quality, and the risk of overflow.
Understanding Context Composition
Most developers may not fully grasp the myriad inputs vying for space in the context window until they conduct a thorough audit. Typically, a production context window comprises several layers, including:
- System instructions — defining the agent’s purpose, rules, tool descriptions, output formats, and illustrative examples. This content is largely static and is ideal for prefix caching.
- Conversation history — a dynamic record of user interactions, agent responses, and tool outputs. This layer often balloons quickly and is frequently neglected by teams.
- Retrieved information — external documents or database entries fetched as needed. Retrievers can also bring back redundant information, consuming budget space that could be allocated for more valuable data.
- Working state — ongoing results, preliminary reasoning, and task progression. Vital for maintaining coherence but can be costly if verbose output is retained.
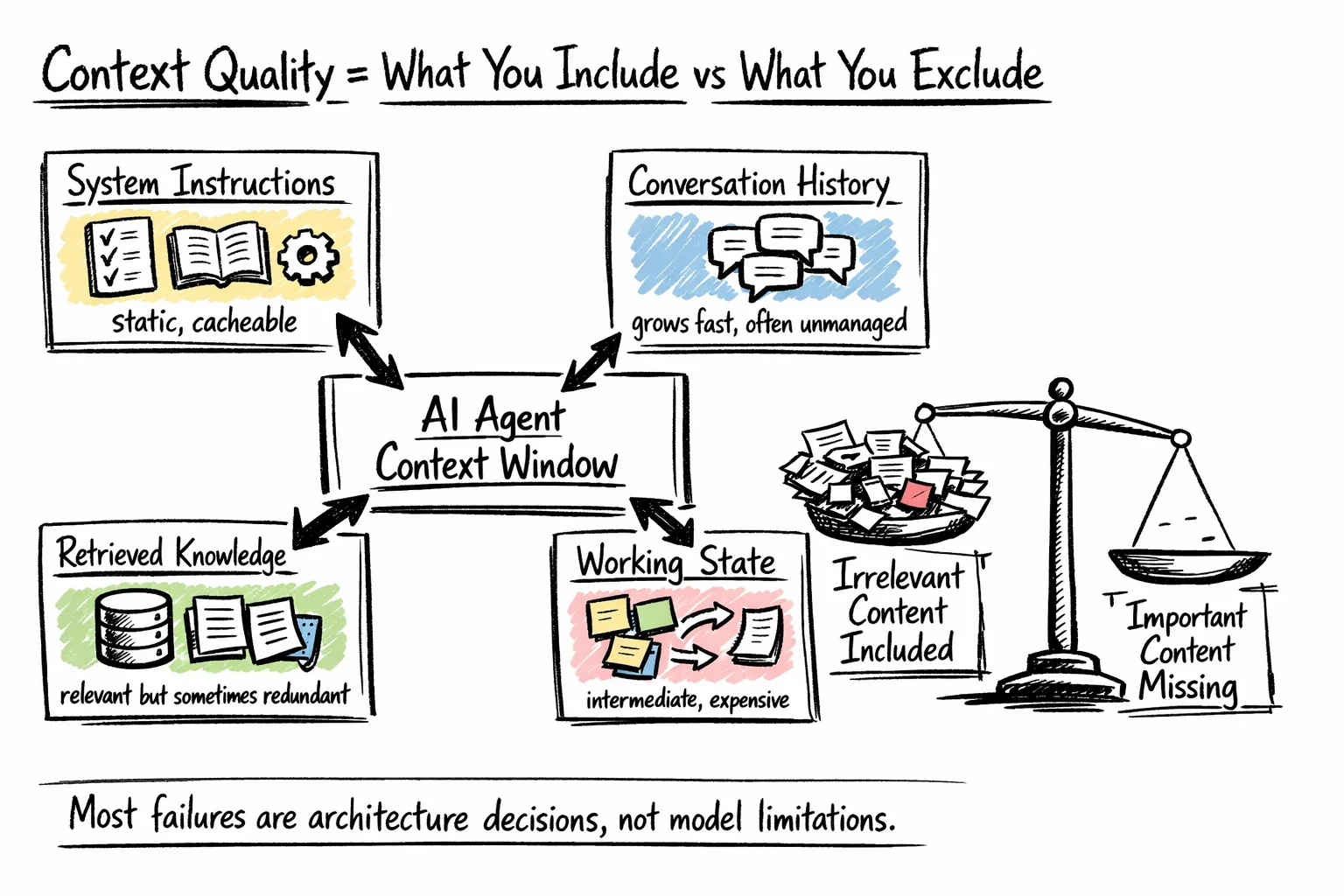
What Compromises the Context Window
The purpose of this audit is not merely to minimize each layer but to appreciate the trade-offs involved. Many context-related production issues stem from one of two decisions: either incorporating irrelevant content into the current step or omitting crucial information. Both issues relate directly to architectural choices rather than flaws in the model itself.
Distinguishing Between Static and Dynamic Context
A significant decision in context management is the distinction between what remains consistent across requests versus what shifts with each interaction.
Static context includes system instructions, agent identity, tool schemas, and fixed rules positioned at the prompt's front. This arrangement facilitates prefix caching, enabling unchanged prefixes to be reused without recalculation during each invocation.
Dynamic context consists of user inputs, recent tool outputs, and newly retrieved documents stored in the variable suffix. This component should remain minimal, limited only to what is necessary for the present reasoning task.
The practical execution of this approach involves a two-pass method for constructing context:
- The initial pass incorporates static context: system prompts, cached instructions, long-standing summaries.
- The successive pass injects dynamic context: the state of the current task, new retrieval outputs, recent history.
Separating these two contexts simplifies debugging. When unexpected behavior arises, one can isolate the issue to either the static setup, often indicating a prompt engineering concern, or the dynamic state, signaling a problem with retrieval or history management.
Overseeing Conversation History
The management of conversation history is often a weak spot in many agent frameworks. Most systems simply append each new interaction, resending the entire conversation for context. While this may suffice for brief sessions, long-term agents face escalating costs and quality challenges.
Context bloat arises as outdated tool outputs, resolved inaccuracies, and obsolete decisions clutter the prompt, consuming tokens without contributing value. Furthermore, context poisoning can occur when prior mistakes are preserved, creating a cascading effect of errors as later reasoning builds upon flawed foundations. For a deeper analysis, refer to How Long Contexts Fail.
Though a simple solution might imply just keeping the last N interactions — a method poised to save costs yet sacrifice crucial long-term context — more sophisticated strategies exist. For instance, rolling summarization creates condensed accounts of older interactions, retaining key decisions and current states over time.
The most comprehensive approach involves anchored iterative summarization, continually updating a structured session-state document that incorporates intent, decisions, actions, and next steps, ensuring vital information remains intact while preventing overflow.
Designing Retrieval as a Strategic Decision
Retrieval processes enable agents to tap into knowledge that would otherwise exceed the scope of the context window. A typical error is viewing retrieval merely as an upstream action — fetching chunks of data and injecting them — without considering the context budget or when retrieval is truly warranted.
Token expenses are frequently underestimated. In workflows involving multiple retrievals, costs can quickly spiral. Optimizing post-retrieval processes by filtering and selecting only the relevant results before they enter the context can greatly enhance efficiency.
The structure of retrieved content is just as important as its relevance. Employing semantic chunking — dividing documents along natural lines of thought rather than fixed sizes — provides better coherence and retains essential meaning. Hybrid retrieval methods, incorporating both semantic searches and keyword filters, can also significantly improve outcomes by targeting requests narrowly, encompassing both semantic relevance and temporal constraints.
A clear design choice involves whether to enable automatic retrieval before each agent prompt or to require the agent to request it as needed:
- Automatic retrieval simplifies processes but may inject unnecessary tokens.
- Agent-triggered retrieval allows for tailored queries at optimal moments within the cognitive sequence but necessitates that the model identify the need for retrieval effectively.
For production systems, opting for agent-controlled retrieval tends to yield better results once the system achieves stability.
Token Budgeting in Multi-Step Agent Cycles
Individual context decisions address only part of the challenge. In multi-step scenarios, token consumption accumulates, demanding a broader budgeting approach that reflects the entire sequence.
Most token expenditures stem from system prompts and tool outputs. Notably, tool responses — especially those related to searches or API calls — constitute a significant cost. The most effective strategy is filtering and streamlining these responses at the time of input rather than compressing outputs afterward, retaining only what is necessary for the next phase.
Aiming for a context utilization rate of roughly 60–80% strikes a balance between optimizing capacity and avoiding waste. Monitoring this in real deployments helps identify budget concerns early. Adjusting allocations dynamically, where simpler tasks utilize less context while complex, multi-step tasks can afford more, fosters a balanced approach to performance and expenditure.
Assessing Context Quality in Production
Failures in context management often evade visibility in standard assessments. An agent might excel during brief test scenarios yet struggle in extended sessions, with errors misattributed to reasoning faults rather than context inaccuracies.
A practical technique to address this is through probe-based evaluation. Following compression or retrieval processes, targeted queries can determine whether critical information was held and accessed correctly. Successful responses can indicate preserved relevant context, while failures can reveal shortcomings in either retrieval or compression quality. Factory.ai’s evaluation framework proposes three types of probes:
- Recall probes: Can the agent retrieve specified facts accurately?
- Artifact probes: Is the agent aware of files it has modified?
- Continuation probes: Can the agent resume multi-step tasks effectively after interruptions?
Some context-specific metrics that merit regular tracking include:
- Context utilization rate — what percentage of the context budget has been effectively used?
- Compression ratio — how many tokens are reduced through summarization measures?
- Retrieval precision — are the chunks retrieved genuinely helpful, or are they ignored once injected?
It's also beneficial to systematically monitor for context drift in ongoing sessions. Symptoms include the agent repeating previously processed files, restating past decisions, or gradually deviating from the initial user objectives. These issues often surface in step-level traces before they manifest in the quality of outputs.
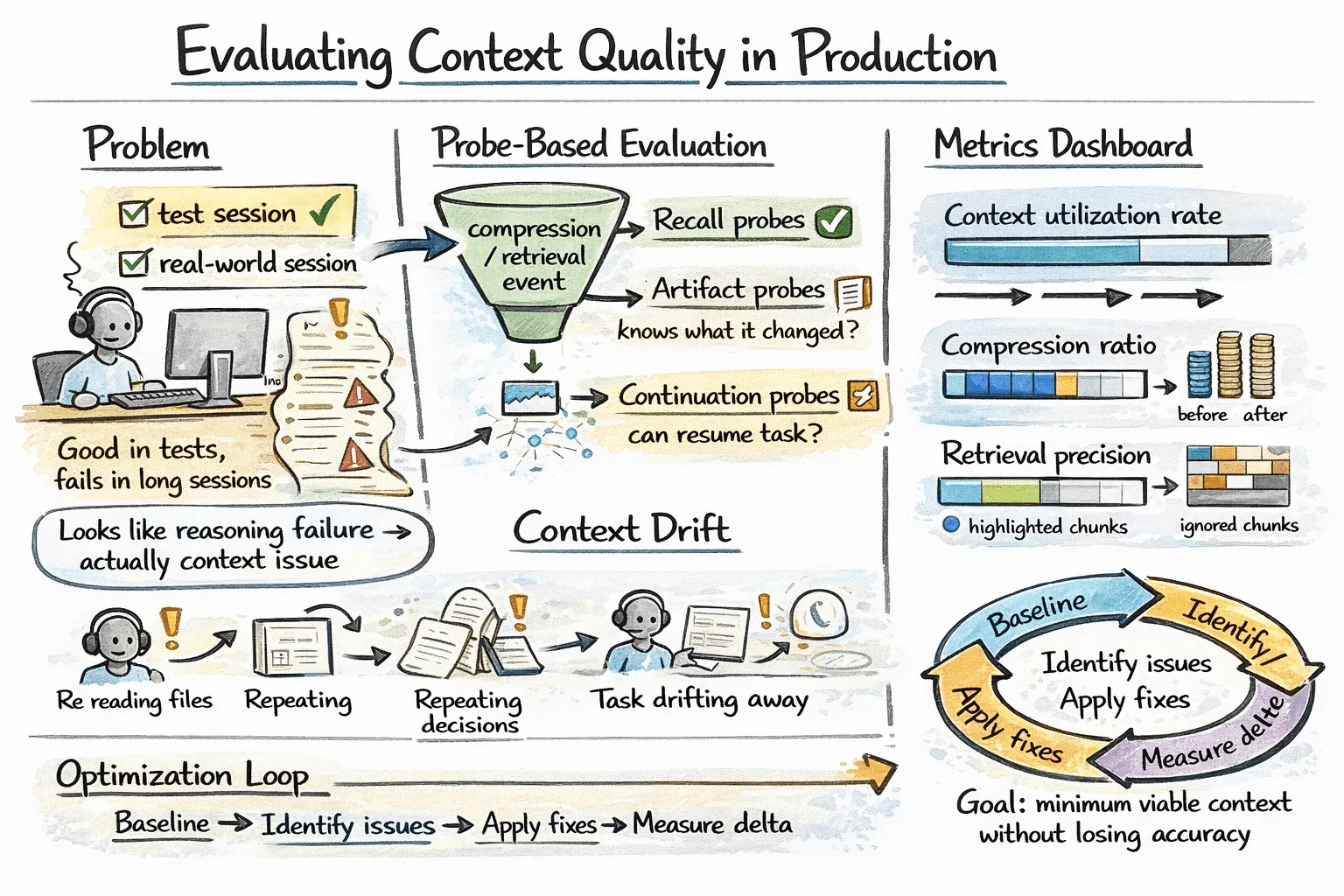
Evaluating Context Quality in Production
Implementing the right optimization cycle involves establishing baseline metrics in real session conditions, identifying high-cost or low-quality segments, applying targeted improvements, and tracking performance impacts.
Although over-compressing can preserve tokens, it risks accuracy and shifts the issue instead of resolving it. The ultimate objective should be to maintain the minimum viable context that allows the agent to succeed in its tasks accurately.
Conclusion
Context management encompasses all facets of agent architecture: content selection, history control, compression processes, retrieval strategies, and token allocation. Every decision taken should be intentional. With advancements in tooling, such as prefix caching, improved summarization techniques, and enhanced retrieval systems, it's clear that the focus must remain on treating context as a precious resource, including only essential components, and validating performance against practical behavior. Below is a recap of the core concepts discussed:
### The Implications of Context Engineering This discussion on context engineering sheds light on a pivotal aspect of AI operations with profound implications for developers and enterprises alike. At its essence, context engineering represents a deliberate strategy to enhance the efficiency and precision of AI systems, especially as they manage complex tasks in real-time scenarios. Consider how the concept of a "context window" fundamentally reframes our understanding of resources in AI. You’re not just throwing data into an AI model; you're crafting a meticulous environment where tokens are treated like a dwindling budget. This method acknowledges both the financial and cognitive costs involved in processing information. If you're navigating this space, recognizing these constraints becomes vital for developing cost-effective and high-performing AI applications. ### Beyond Raw Data: Structure and Management Moreover, the importance of structuring context cannot be overstated. By differentiating between static and dynamic layers—where fixed information is cacheable and dynamic data adjusts per task—developers can harness more reliable outputs. This dual-layer framework encourages not merely the accumulation of knowledge but its judicious management. Techniques like summarization and truncation help prevent blunders that stem from unnecessary data bloat. Are you still relying on old models of storage? It might be time to rethink that strategy. ### Navigating Metrics and Evaluation As we look to assess the effectiveness of these strategies, tracking critical metrics will provide a pathway for continuous improvement. Setting parameters around utilization rates, retrieval precision, and context drift gives a holistic view of system performance. Are you using probe-based tests effectively? If not, you could be missing out on key insights. Given all these considerations, it’s clear that context engineering is more than just a technical nuance; it’s a method that has the potential to redefine how AI interacts with data. As our understanding deepens, these insights will not only drive innovation in AI development but will also ensure that we’re equipped for the challenges that lie ahead. For those eager to dive deeper into this subject, there are valuable resources available, such as Anthropic's detailed guide on effective context engineering and an informative article on context engineering by Weaviate. These can further your grasp of how to optimize AI performances effectively. The future of AI depends on proactive and strategic thinking in context management. It’s up to you to leverage this knowledge and shape your projects accordingly.
