Introduction
When using agentic loops in production environments, costs can escalate quickly. For anyone involved in AI development or deployment, understanding these costs is essential. Both large language models (LLMs) and external services tied to AI consume resources, with billing often determined by token usage, which can lead to budget surprises.
Enter prompt compression—a powerful technique designed to mitigate these financial pressures. This article breaks down the theory and implementation of various prompt compression methods. By the end, you'll be equipped to better manage costs associated with agentic loops.
Why Care About Prompt Compression?
In many frameworks, such as LangGraph or AutoGPT, maintaining a complete context is standard practice as agents process multiple steps in problem-solving. Imagine a scenario where an agent must execute 20 steps; it might start needing to send 500 tokens. By the second step, it's sending those same 500 tokens plus another 1,000 tokens—bringing the total to 1,500. As you can see, it’s easy for these costs to spiral, especially when you’re transmitting increasingly redundant information.
While it may appear that token usage grows linearly, the reality is much more alarming—the cumulative cost actually escalates quadratically. This means that as you push through long loops, costs can balloon unexpectedly. Here’s where prompt compression techniques become invaluable, deploying strategies like selective context or summarization to rein in those expenses.
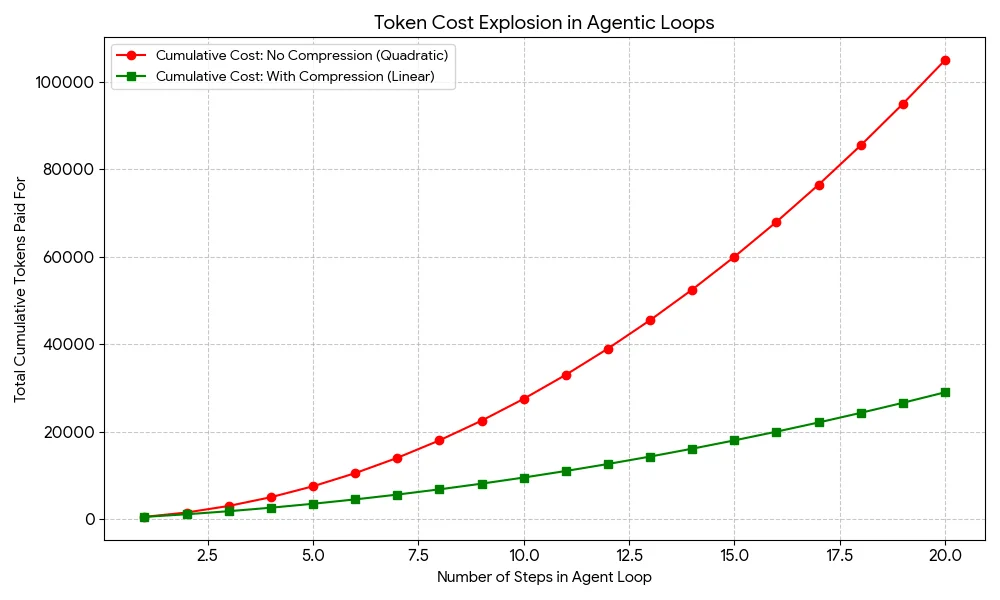
Cost curve of agentic loops: without vs. with prompt compression
The stakes of this issue extend beyond dollars and cents. There's also the hidden cost related to latency. Longer prompts take more time to process, and that's not something users are always willing to endure. By compressing prompts, you can achieve faster response times while reducing computational overhead.
To illustrate the potency of prompt compression, consider that a context requiring 500,000 tokens could potentially be reduced to a mere 32,000 tokens, while still preserving essential information. This reduction typically involves stripping away elements like repetitive JSON structures, stop words, and less impactful conversational segments. Let's explore practical implementation strategies that could anchor your prompt compression efforts:
- Instruction distillation: This technique involves crafting a condensed version of lengthy system prompts, simplifying them into symbols or shorthand that the model can easily parse.
- Recursive summarization: Utilize either the agent itself or a less resource-intensive model, such as Llama 3 or GPT-4o-mini, to periodically compress context into succinct summaries, ensuring that only the critical elements are preserved as the interaction progresses.
- Vector database (RAG) for history retrieval: Rather than resend a complete history every time, this technique leverages a local vector database like FAISS or Chroma to retrieve only the most relevant actions, optimizing data handling.
- LLMLingua: This emerging framework focuses on identifying and removing “non-essential” tokens from prompts before they reach the more resource-intensive language model.
Optimizing Token Usage
The code snippet presented provides a strategy for streamlining the accumulation of actions into a coherent summary, effectively reducing the cost associated with token usage in each iteration. This approach is particularly relevant in practical applications where deploying a smaller, less expensive language model—such as Llama 3—can handle the summarization task without significantly sacrificing quality in understanding.
The Essence of Distillation
Here’s an interesting takeaway regarding the technique of "distillation." Consider a verbose prompt that takes up 42 tokens: “You are a helpful research assistant. Your goal is to find information about X. Please provide your output in a valid JSON format and do not include any conversational filler.” This can be refined down to a streamlined 12-token prompt: “Act: ResearchBot. Task: Find X. Output: JSON. No fluff.” The implications of this reduction are striking; a process that includes numerous steps—say, about 100—could see savings of up to 3,000 tokens just from this one aspect alone.
Compression in Action
Throughout a simulated loop, the code captures and reports full context token usage, documenting how each iteration accumulates more tokens. Early iterations start at 37 and climb to 109 by the final loop, emphasizing how quickly complexity can grow. Following compression, the significant reduction to just 36 tokens highlights the resource-saving potential of this approach. The output clarifies it further: if you track the token counts, you'll notice that compressing the context doesn’t just make things cheaper; it also makes your model far more efficient.
The stark contrast between the uncompressed and compressed totals—showing a whopping 67% savings—cannot be overlooked. It’s clear that by employing these techniques, you can maintain operational efficiency without burdening your costs with unnecessary token count.
Final Thoughts
The implications of prompt compression in AI are far from trivial—it's becoming essential for any system aiming to operate efficiently over time. Tackling the quadratic cost problem is no longer an option but a prerequisite for scalable technologies. The techniques discussed, ranging from instruction distillation to RAG-based history retrieval and LLMLingua, each provide unique avenues for cutting down processing time and expenses.
Here's the kicker: If you pair recursive summarization with a distilled system prompt, you can significantly reduce token consumption without needing fancy new infrastructures. The potential here is staggering; as evidenced by a recent example, savings can soar as high as 67%.
This marks a turning point for those deploying agentic systems. If you’re working in this space, adopting these strategies isn’t just advisable—it’s imperative. A failure to innovate in this area could lead to unsustainable costs and operational lag.
Looking ahead, the continual refinement of these methodologies will likely redefine how we approach AI optimization and cost efficiency. As systems become more intricate, the need for effective prompt management will only intensify. The future isn’t just about creating more advanced systems; it’s about making them operate smarter and at lower costs. Keep an eye on developments in this area; they could very well shape the next wave of AI applications.

